f4b1069
Nuovo Utente
- Registrato
- 7/1/08
- Messaggi
- 130
- Punti reazioni
- 9
Buongiorno a tutti,
sto cercando di imparare ad usare R e a lavorare in modo un po' piu' "matematico" e statistico.
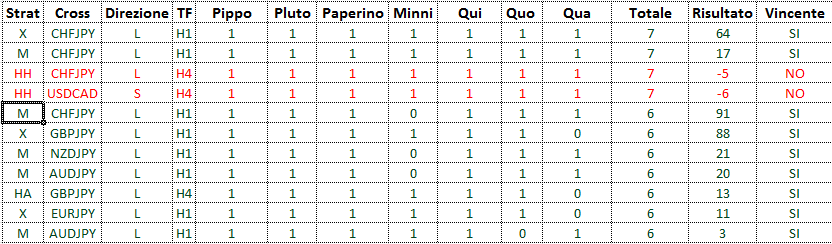
Nell'ultimo periodo per ogni trade che faccio mi segno alcuni parametri (Pippo,Pluto,Paperino,Minni,Qui,Quo,Qua) relativi alla trade.
Se questi parametri sono rispettati segno un 1 se no uno 0. Ho anche una colonna con la somma di questi parametri (TOTALE)
Ho una colonna Vincente (SI/NO) a seconda che la trade sia andata bene o male e una colonna risultato con il risultato in PIPS.
[Figura in basso]
Ora, vorrei vedere se e come questi parametri influiscono sui miei risultati (al momento ho circa 200 trades in archivio...)
Grazie agli ottimi aiuti di CREN e SURCONTRE ho iniziato a pasticciare con "R".
Al momento con un t.test verifico se ci sono differenze significative nelle variabili (per esempio Minni) in relazione a VINCENTE.
*****************************************************************************************************************************************
> t.test(Minni~Vincente, alternative='two.sided', conf.level=.95,
+ var.equal=FALSE, data=dati__version_1_)
Welch Two Sample t-test
data: Minni by Vincente
t = 2, df = 8, p-value = 0.08052
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.05100069 0.71766736
sample estimates:
mean in group NO mean in group SI
1.0000000 0.6666667
*****************************************************************************************************************************************
E valuto il livello del p-value per verificare significativita'.
Questo procedimento lo faccio per tutte le variabili in relazione con VINCENTE.
Le mie domande sono queste (considerate che sono all'ABC di R e della statistica....) non infierite per favore
Sto facendo una cosa corretta (valutando differenze statisticamente significative delle medie rispetto al risultato) per valutare quali variabili tenere maggiormente presenti prima di entrare in una trade ?
Quanti record (che campione) dovrei avere per avere una statistica accettabile ?
C'e' un modo (con R) per verificare in un solo passaggio differenze significative della media (una sorta di t-test ma contemporaneo su tutte le variabili contro VINCENTE) al posto di fare il t-test per ogni variabile ? Eventualmente mi sapreste indicare qualche comando ?
Come posso verificare l'influenza delle variabili (Pippo, Pluto, etc) rispetto alla variabile Risultato che non e' (SI/NO) ma numerica ?
Per approfondire .... mi sapreste indicare un testo che mi prenda per mano nella statistica e mi dia una base consistente ?
Ho gia' visto l'ottimo thread di Ernesto .. ma cercavo un testo di riferimento per statistica di base.
Ogni suggerimento e' bene accetto.
Vi ringrazio.
sto cercando di imparare ad usare R e a lavorare in modo un po' piu' "matematico" e statistico.
Nell'ultimo periodo per ogni trade che faccio mi segno alcuni parametri (Pippo,Pluto,Paperino,Minni,Qui,Quo,Qua) relativi alla trade.
Se questi parametri sono rispettati segno un 1 se no uno 0. Ho anche una colonna con la somma di questi parametri (TOTALE)
Ho una colonna Vincente (SI/NO) a seconda che la trade sia andata bene o male e una colonna risultato con il risultato in PIPS.
[Figura in basso]
Ora, vorrei vedere se e come questi parametri influiscono sui miei risultati (al momento ho circa 200 trades in archivio...)
Grazie agli ottimi aiuti di CREN e SURCONTRE ho iniziato a pasticciare con "R".
Al momento con un t.test verifico se ci sono differenze significative nelle variabili (per esempio Minni) in relazione a VINCENTE.
*****************************************************************************************************************************************
> t.test(Minni~Vincente, alternative='two.sided', conf.level=.95,
+ var.equal=FALSE, data=dati__version_1_)
Welch Two Sample t-test
data: Minni by Vincente
t = 2, df = 8, p-value = 0.08052
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.05100069 0.71766736
sample estimates:
mean in group NO mean in group SI
1.0000000 0.6666667
*****************************************************************************************************************************************
E valuto il livello del p-value per verificare significativita'.
Questo procedimento lo faccio per tutte le variabili in relazione con VINCENTE.
Le mie domande sono queste (considerate che sono all'ABC di R e della statistica....) non infierite per favore
Sto facendo una cosa corretta (valutando differenze statisticamente significative delle medie rispetto al risultato) per valutare quali variabili tenere maggiormente presenti prima di entrare in una trade ?
Quanti record (che campione) dovrei avere per avere una statistica accettabile ?
C'e' un modo (con R) per verificare in un solo passaggio differenze significative della media (una sorta di t-test ma contemporaneo su tutte le variabili contro VINCENTE) al posto di fare il t-test per ogni variabile ? Eventualmente mi sapreste indicare qualche comando ?
Come posso verificare l'influenza delle variabili (Pippo, Pluto, etc) rispetto alla variabile Risultato che non e' (SI/NO) ma numerica ?
Per approfondire .... mi sapreste indicare un testo che mi prenda per mano nella statistica e mi dia una base consistente ?
Ho gia' visto l'ottimo thread di Ernesto .. ma cercavo un testo di riferimento per statistica di base.
Ogni suggerimento e' bene accetto.
Vi ringrazio.