 I principali indici azionari hanno vissuto una settimana turbolenta, caratterizzata dalla riunione della Fed, dai dati macro importanti e dagli utili societari di alcune big tech Usa. Mercoledì scorso la Fed ha confermato i tassi di interesse e ha sostanzialmente escluso un aumento. Tuttavia, Powell e colleghi potrebbero lasciare il costo del denaro su livelli restrittivi in mancanza di progressi sul fronte dei prezzi. Inoltre, i dati di oggi sul mercato del lavoro Usa hanno mostrato dei segnali di raffreddamento. Per continuare a leggere visita il
I principali indici azionari hanno vissuto una settimana turbolenta, caratterizzata dalla riunione della Fed, dai dati macro importanti e dagli utili societari di alcune big tech Usa. Mercoledì scorso la Fed ha confermato i tassi di interesse e ha sostanzialmente escluso un aumento. Tuttavia, Powell e colleghi potrebbero lasciare il costo del denaro su livelli restrittivi in mancanza di progressi sul fronte dei prezzi. Inoltre, i dati di oggi sul mercato del lavoro Usa hanno mostrato dei segnali di raffreddamento. Per continuare a leggere visita il Key West
Sig.E inside-beware!
- Registrato
- 8/1/13
- Messaggi
- 1.625
- Punti reazioni
- 61
Quanto materiale interessante!!

Ma..ribadisco.
Vorrei fare una cosa semplice e tentare di cucirla ad una realtà "reale".
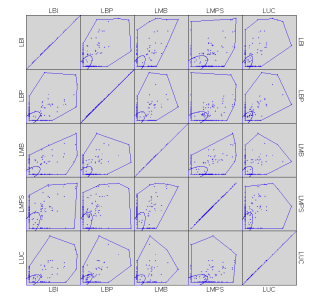
Come abbiamo visto, qualsiasi distribuzione venga usata..(rimando all'esempio "banche tutte -30%..stimare la probabilità congiunta) la DP by Copula Approach utilizzata in maniera canonica restituisce stime irreali.
Proabilità "quasi nulla" quando...cribbio, è tutt'altro che nulla...ricorda quella minKiata Made in China che attribuiva probabilità"quasi nulla" all'insolvenza generalizzata dei mutuatari (e collaterali)
Essendo io barbiere..posso permettermi di esprimere tutta la creatività che impiego nel mio lavoro trattando i numeri.
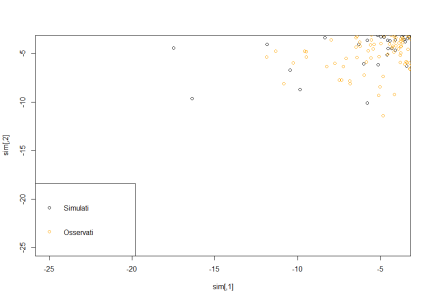
Ok..mi pare cmq. di capire che concordate sulla copula empirica in 2 righe di codice..ed è già un passettino avanti. Ora provo a calcolare queste benedette probabilità "brutte" e farle stare in "tre" righe di codice...")
Provo...mica so sicuro..
Musica, grazie dei contributi che leggerò avidamente!
Ma..ribadisco.
Vorrei fare una cosa semplice e tentare di cucirla ad una realtà "reale".
Come abbiamo visto, qualsiasi distribuzione venga usata..(rimando all'esempio "banche tutte -30%..stimare la probabilità congiunta) la DP by Copula Approach utilizzata in maniera canonica restituisce stime irreali.
Proabilità "quasi nulla" quando...cribbio, è tutt'altro che nulla...ricorda quella minKiata Made in China che attribuiva probabilità"quasi nulla" all'insolvenza generalizzata dei mutuatari (e collaterali)
Essendo io barbiere..posso permettermi di esprimere tutta la creatività che impiego nel mio lavoro trattando i numeri.
Ok..mi pare cmq. di capire che concordate sulla copula empirica in 2 righe di codice..ed è già un passettino avanti. Ora provo a calcolare queste benedette probabilità "brutte" e farle stare in "tre" righe di codice...
Provo...mica so sicuro..
Musica, grazie dei contributi che leggerò avidamente!