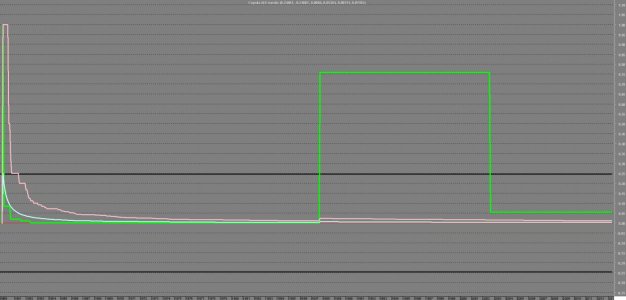
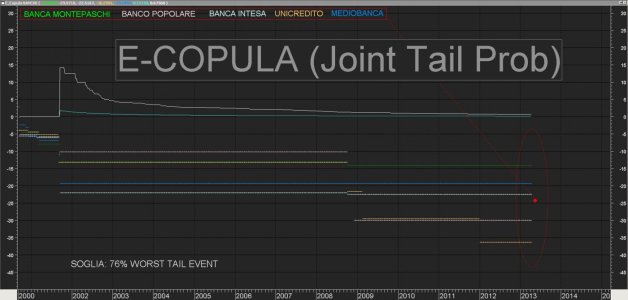
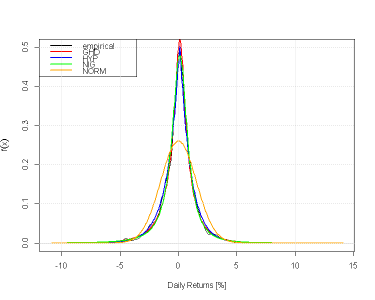
Allora, come avrei pensato di risolvere il problema:
Vglio stimare la probabilità congiunta relativa alle 5 banche cui sopra di subire un Tail Risk Event pesante.
"Pesante" lo identifico arbtrariamente pari al 76% del peggior loss subito dalle 5 banche.
Se,
se..tutte e 5 le banche mi mettono a segno una perdita maggiore della soglia cui sopra nella stessa settimana (o giorno, o mese), in base a quanto osservo sono sicuramente in presenza di una Tail Dependence.
Il listato si condensa in un paio di righe, l'ho già inviato a Paolo che spero lo controlli e, se ritenuto corretto, possa tradurlo per excel (come Cren, se lo ritiene corretto e conforme al concetto di Copula empirica che stiamo affrontando, potra tradurlo in "R")
Caricate le 5 Serie:
sec:=Security("C:\ftse mib 40\bmps.mi",C);R1:=100*Log(SEC/Ref(SEC,-1));sec:=Security("C:\ftse mib 40\bp.mi",C);R2:=100*Log(SEC/Ref(SEC,-1));sec:=Security("C:\ftse mib 40\isp.mi",C);R3:=100*Log(SEC/Ref(SEC,-1));sec:=Security("C\ftse mib 40\ucg.mi",C);R4:=100*Log(SEC/Ref(SEC,-1));
sec:=Security("C\ftse mib 40\mb.mi",C);R5:=100*Log(SEC/Ref(SEC,-1));
lb:=Input("Tail Event % Congiunto:",-100,100,76);lb:=lb/100; fissiamo la soglia che identifica la "gravità" dell'evento
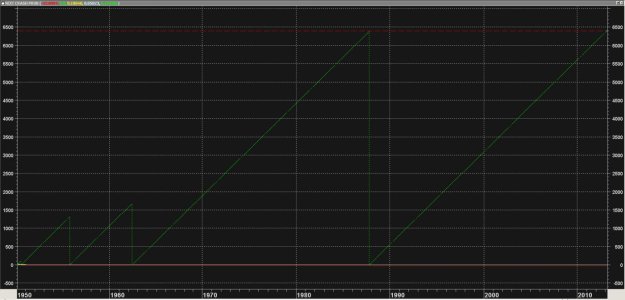
lst:=Lowest(r1);lst*lb; Calcoliamo il minimo (pari valore di soglia imposto) toccato da bmps in questo caso e lo plottiamo
mp1:=If(r1<Ref(lst*lb,-1),1,0); Calcoliamo la marginale identificando l'evento "minimo> minimo precedente", il nostro "Tail Event"
***** ripetiamo per le rimanenti serie*****
lst:=Lowest(r2);lst*lb;
mp2:=If(r2<Ref(lst*lb,-1),1,0);
lst:=Lowest(r3);lst*lb;
mp3:=If(r3<Ref(lst*lb,-1),1,0);
lst:=Lowest(r4);lst*lb;
mp4:=If(r4<Ref(lst*lb,-1),1,0);
lst:=Lowest(r5);lst*lb;
mp5:=If(r5<Ref(lst*lb,-1),1,0);
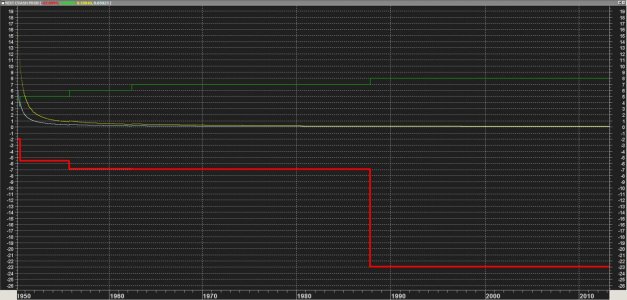
dt:=If(r1<0 AND r2<0 AND r3<0 AND r4<0 AND r5<0,1,0); Contiamo i giorni che hanno visto le 5 serie chiudere negative.
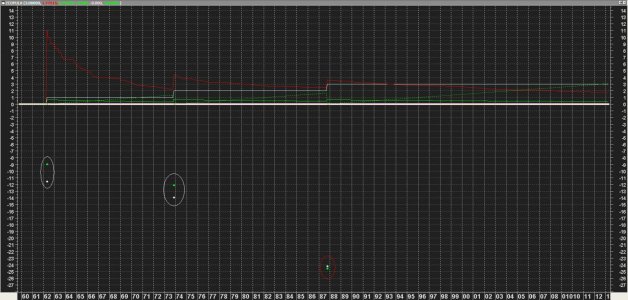
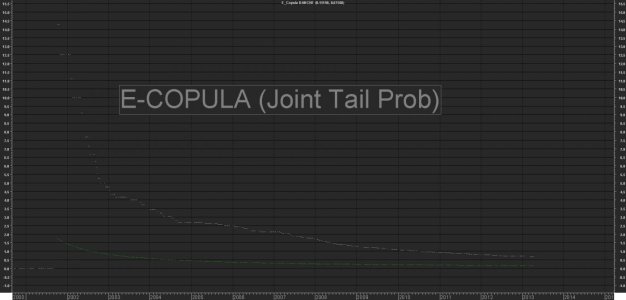
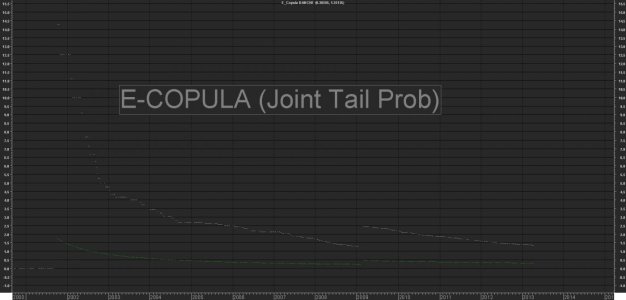
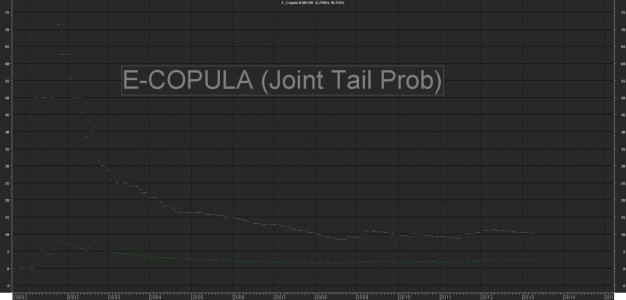
Cum(mp1*mp2*mp3*mp4*mp5)/Cum(1)*100; Calcoliamo la probabilità congiunta. Se abbiamo dati allineati e puliti li troviamo già "in riga" ed è sufficiente moltiplicare il valore binaro assegnato ad ognuna di esse, cumularlo e dividerlo per il numero di osservazioni (l'intero campione in questo caso)
Cum(mp1*mp2*mp3*mp4*mp5)/Cum(dt)*100; Come sopra ma tenendo conto dei soli giorni "negativi"
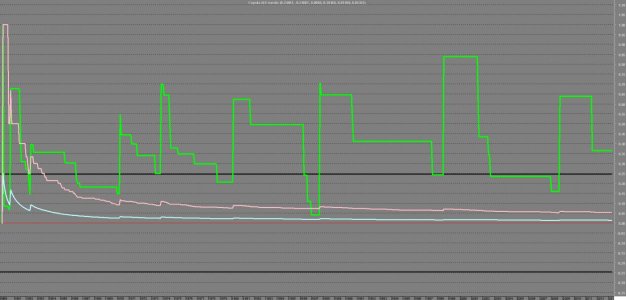
Deduciamo (guardando il grafico sopra) che:
in base all'ampiezza dello storico prescelto le 5 banche hanno una probabilità congiunta di subire un "Heavy Tail Event" , che possiamo identificare in una perdita minima per ognuna di esse compresa tra un valore > -14%circa ed un valore >-36% circa pari a
0.15% su tutto il campone
0.67% se considero i girni negativi per tutte.
Perchè uso > >; perchè non credo di fare un'operazione sbagliate ipotizzando una perdita media "minima" pari alla media dei 5 valori negativi rilevati.
Noterò che, alzand la soglia ho probabilità nulla (ovvero mai è accaduto che abbiano messo a segno perdite >76% del loro peggir loss) , diminuendo la soglia e diminuendo la "gravità" dell'evento, osserverò una maggiore dipendenza e maggiore(ovviamente) Joint Tail Risk Prob.
Il tutto, si infila in una matrice di Tail Similarity (Cosine Similarity..che nell'esempio Dax Sp500 è calcolata dinamicamente) e può venir utilizzato per scopi che andremo ad esaminare in seguito.
Intanto, attendo correzioni prima di proseguire..mancano ancora un sacco di cose..il tempo..maledetto tempo...
")
Spero sia chiaro che la "probabilità nulla" assoluta è esclusa. Come deve essere.
Musica:
nb
al teorema di Sklar , soddisfatto da quanto sopra, abbiamo che:
The theorem also states that given F(x1,x2), the copula is unique on Range(F1)*Range(F2)
, which is the Cartesian product of the ranges of the marginal CDF’s.
 I principali indici azionari hanno vissuto una settimana turbolenta, caratterizzata dalla riunione della Fed, dai dati macro importanti e dagli utili societari di alcune big tech Usa. Mercoledì scorso la Fed ha confermato i tassi di interesse e ha sostanzialmente escluso un aumento. Tuttavia, Powell e colleghi potrebbero lasciare il costo del denaro su livelli restrittivi in mancanza di progressi sul fronte dei prezzi. Inoltre, i dati di oggi sul mercato del lavoro Usa hanno mostrato dei segnali di raffreddamento. Per continuare a leggere visita il
I principali indici azionari hanno vissuto una settimana turbolenta, caratterizzata dalla riunione della Fed, dai dati macro importanti e dagli utili societari di alcune big tech Usa. Mercoledì scorso la Fed ha confermato i tassi di interesse e ha sostanzialmente escluso un aumento. Tuttavia, Powell e colleghi potrebbero lasciare il costo del denaro su livelli restrittivi in mancanza di progressi sul fronte dei prezzi. Inoltre, i dati di oggi sul mercato del lavoro Usa hanno mostrato dei segnali di raffreddamento. Per continuare a leggere visita il