Sig. Ernesto
Nuovo Utente
- Registrato
- 14/8/01
- Messaggi
- 21.247
- Punti reazioni
- 807
Follow along with the video below to see how to install our site as a web app on your home screen.
Nota: This feature may not be available in some browsers.
Hai provato:
getSymbols(c('^gdaxi', '^gspc'))
?
")

Cosa poi ci farai non lo so, ma di solito queste cose fanno impazzire gli econometristi: fino a 10 anni si divertivano con Markowitz, poi sono passati tutti in massa a BL. Da un paio d'anni a questa parte sono di moda i Minimum Variance Portfolio, chissà cosa scoveranno nei prossi anni con i loro pregevoli esercizi di data-snooping di modello
Happy trading
ata Mining Algorithms In R - Wikibooks, open books for an open worldeccovi un po di link per R:
R Cookbook - Code
RDataMining.com: R and Data Mining
R/Finance 2012: Applied Finance with R
Revolutions
R-bloggers | R news & tutorials from the web
Category
Stock Analysis using R | (R news & tutorials)
https://www.rmetrics.org/
R, Ruby, and Finance
a Physicist in Wall Street
quantmod: Quantitative Financial Modelling Framework
io uso R da diverso tempo quindi se avete problemi chiedetemi o scrivetemi a adalpozz@ulb.ac.be
bye
Andrea
Tu sai, vero, che questa mossa che hai appena fatto è la tua fine, no?io uso R da diverso tempo quindi se avete problemi chiedetemi o scrivetemi a adalpozz@ulb.ac.be
Eccolo! Stavo proprio per scrive di là (ma sono così bannato che diviene sempre più complicato..)
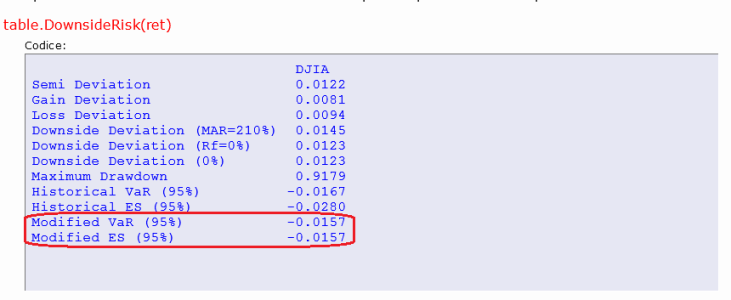
Le misure di downside, hai notato?
Modified VaR e Modified CVaR, strani perchè uguali (e non è possibile) e strani perchè bassini rispetto a VaR e CVaR simulazione storica.
Secondo te perchè?
(sto riguardando quel che posso tempo permettendo..onde non imbarcarmi in qualcosa di sbagliato a priori..)
Allora;
"R" utilizza per il calcolo della Expected Shortfall modificata l'approssimazione di Edgeworth. Ovvero, utilizza l'espansione per calcolare la probabilità di ottenere valori superiori all'intervallo proposto dal MVaR mediante i quantili dell'espansione di Cornish Fisher.
Accade che l'approssimazione di Edgeworth alla funzione di densità tende a zero quando viene applicata a valori fortemente negativi(forti perdite). Questo comporta che il risultato potrebbe essere addirittura inferiore al al valore di Modified VaR. Lo stratagemma usato dai Professori "padri" di R è lo stesso che abbiamo intuito anni fa sul MVaR. Si fissa il valore minimo pari al valore del VaR(o in questo caso del MVaR) e si fanno coincidere le probabilità se la stima risulta inferiore.
In questo caso, ripeto, poichè R ha stimato sul Dow Jones un CVaR Modificato inferiore al valore stimato col VaR Modificato..e ciò è inammissibile, lo pone uguale al valore di quest'ultimo (spingendo..nel caso l'utilizzatore fosse interessato alla misura) a procedere con una diversa metodologia di stima.
Da qui, l'attenzione da porre se usate tali misure per ratio di performance. Controllate prima.
Si risolverebbe il tutto con un'operazione di winsorizing dei dati, ma in questo caso equivarrebbe a limitare perdite effettivamente registrate..e non è proprio intelligente come procedura(IMHO).
O forse aumentare i termini dell'aprossimazione (che credo =1)(IMHO2)..ma sono cose complicatissime per me..per cui lascio la palla a Cren o Andrea
R: calculates Expected Shortfall(ES) (or Conditional Value-at-Risk(CVaR) for univariate and component, using a variety of analytical methods.