alextolomei
Nuovo Utente
- Registrato
- 17/12/11
- Messaggi
- 275
- Punti reazioni
- 10
Puoi spiegarmi in parole povere cosa volevi dire?
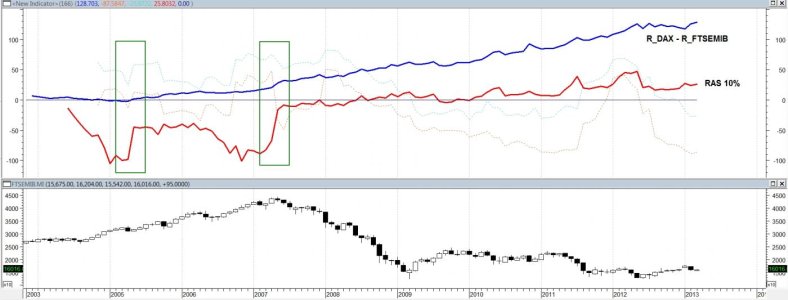
spero non andare troppo in ot epicureo ma mi sembra giusto concludere quanto ho iniziato con la mia interpretazione.
Puoi calcolare la probabilità su un lancio di dado, con raffiche di vento forte, con la statistica frequentistica?
Hai indipendenza stocastica solo sul solito campo in probabilità condizionata. Se la variazione avviene attraverso variabili di un altro campo (eventi di interesse) l'effetto non dipende dagli eventi in esame e ne modifichi la probabilità, meglio quindi usare bayes (tips).
Correlare e stabilizzare modelli matematici di lorenz con le copule è probabile ma tra diversi campi è altamente improbabile.
in ambito ristretto concordo che la copula è uno strumento potente e l'utilizzo ha solo benefici. Quando preso di riferimento da tutto il sistema finanziario è pericoloso a causa dell'isomorfismo.
Una notizia fondamentale, attacco biochiochimico in us, libero arbitrio, malattie incurabili, avidità, paura, demenza, clima, evento naturale. .ecc.. Queste situazioni possono essere non correlate ma quando è simmetrico al settore finanziario (evento di interesse) la copula non li separa, li integra e li correlaziona.
calcolando le correlazioni multiple di tutta la domanda e offerta del settore finanziario. Tutte! Il modello si correlaziona a catena. Curtosi o no il grado di correlazione della copula è talmente ampio che direttamente o indirettamente ogni elemento è coinvolto. La reazione a catena è irreversibile, una qualsiasi modifica aumenta solo la sua catena. reagire al quando si verifica non ha un come se è inevitabile.
L'intero sistema finanziario non è influenzato da tutti gli eventi, o meglio lo è ma l'entità è misurabile in arco di tempo circoscritto che si devia rapidamente prima che riprenda il suo normale corso. Eventi più importanti possono modificarne la struttura invalidando il modello.
Un unico modello generale che non separa l'indeterminabilità, o meglio non partiziona i campi, è poco credibile.
")