(Ho cancellato i links Cren perchè non voglio nulla che possa ricondurre a quel postribolo. In cambio tuttavia, ho posto una domanda che nel postribolo non avrebbero mai fatto, vista la scarsa attitudine a "capire" prima di "esibire".
Non sono assolutamente d'accordo, oltre ad essere contrario a queste forme di censura: in primo luogo perchè il destinatario del mio riferimento era .::michele::. che poteva avere tutto l'interesse a leggere certe cose, non era "pubblicità" gratuita ad un altro sito; in secondo luogo sono contrario a forme di censura arbitrarie a giudizio del singolo senza che prima si sia almeno discussa pubblicamente l'opportunità o meno della cancellazione.
Insomma, hai cancellato un mio messaggio potenzialmente utile per un altro lettore perchè tu ritieni che si trovi in un
forum di scarsa qualità.
Non va bene

Sinceramente non ho affatto apprezzato questa censura, è il genere di episodi che mi fa passare la voglia di contribuire alle discussioni.
Per me non c'è relazione di preferenza tra le "piazze", scrivo dove leggo argomenti stimolanti e dove penso di poter dare un contributo e/o approfondire le mie competenze.
Spero si tratti di un caso isolato, che non si ripeterà.
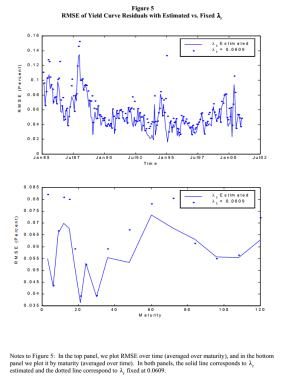
Mi scusino..ma sto lambda Diebold e Li lo tengono fisso per un motivo o sono degli sprovveduti???
Grazie Crengi, rispondimi su Diebold Li che mi interessa molto
")
La mia opinione è sempre quella di lasciar parlare i dati il più possibile; quindi Diebold e Li fissano un parametro di firma
ex ante sulla base di un buon
fitting ma è chiaramente una soluzione non ottimale.
La mia impressione è che, da quando l'econometria si è impossessata della rappresentazione spazio-stato e del filtro di Kalman, cerchi di usarli per qualsiasi cosa, anche dove non strettamente necessari.
Osservando a posteriori i risultati della mia stima tempo-variante di
λ, e confrontandoli con le figure allegate al documento di .::michele::., ho notato che effettivamente la stima mediante filtro di Kalman assumendo
λ fattore latente è più pulita rispetto alla spezzata che ho prodotto io.
Tuttavia, osservando come
λ influisce nel Nelson-Siegel e qual è il
range di valori in cui spazia, la mia impressione è che l'impatto di questa soluzione sia realmente minimo: ovvero, se la stima mediante filtro di Kalman fosse anche solo più problematica di copiare una riga di codice e allungasse i tempi di elaborazione in modo spropositato, me ne sbatterei le balle e mi concentrerei molto di più sulle variabili macroeconomiche che possano spiegare il movimento della
yield curve (documento di TheBear).